

Whilst everyone is talking about AI and what it can do, there is very little out there that deals with how it can be adopted within a business.
What does it take to implement, and what do I need to consider from a development and management perspective?
With today’s AI-hype, one could presume that the development of Artificial Intelligence or Machine Learning is as easy as it is to develop a website today.
Salesforce.com has released Einstein, through acquisition, and is obviously positioning its offering within the context of CRM data. Though Einstein can only address certain problems at the moment, such as image recognition and customer service “bots”. It cannot be easily adapted to create a whole new model such as evaluating the validity of an insurance claim submitted via Salesforce Communities for example. It requires sophisticated development. I’m sure Salesforce’s research teams will be working hard to address this.
Google Cloud Platform, Amazon AWS, and Microsoft Azure all have Machine Learning compute services, which are absolutely necessary due to the GPU and Memory requirements of AI and ML, but again this relies on your business having the capacity to choose and develop the appropriate Machine Learning or Deep Learning models and then releasing them to these environments. Which highlights a good point that if your organisation hasn’t adopted a cloud compute strategy, you will likely be at a disadvantage when it comes to AI and ML development.
Frameworks have taken up a lot of the heavy lifting. Tensorflow, Keras, Caffe, Torch et al. are all a “god-send” for development, and each has its strengths (link). But they are just frameworks, which abstract away the complexity of the underlying mathematics that powers AI and ML (see matrix mathematics and back-propogation as examples), they still require considerable data processing and coding.
So it is unlikely that the future will see any of the aforementioned vendors release a simple and intuitive solution for general Deep Learning and Machine Learning development. Therefore its best to understand how to approach this within our organisations.
There are four important aspects that need careful planning and execution. Failure to undertake such care will lead to either failing to deliver the solution, or worse still, a solution that over time fails to meet the accuracy expected. The latter being disastrous in some scenarios. So here are the areas;
A. Understand your “why”
Foremost in the process is being very clear about the Question we are seeking to answer with Machine Learning or our Deep Learning implementation. The right question will drive data selection, algorithm and framework best for your environment.
B. Understand your Data Sources
In seeking to answer our question, the identification of data sources can be a lengthy process. It requires identifying our source data, shaping the data to suit our model type, and validating our data. If you’re interested in learning more about shaping data for this purpose, a good start is Tidy Data by Hadley Wickham that a colleague of mine put me onto.
Companies that already have a mature data pipeline and BI environment will be part the way there. Data pre-processing is a skill and requires a good toolkit. In future I predict you will see companies such as Zoomdata building real-time data pipelines specifically to support Deep Learning implementations – watch this space.
C. Correct Algorithm Selection
Not all algorithms are created equal, and there are a plethora of algorithms (here, here) that are best for different problem domains. This is where a sizable amount of time must be invested. It will determine whether Deep Learning algorithms (ReLU, Softmax or both etc), or Machine Learning (KNN, SVM, or K-Means clustering etc) algorithms are appropriate, each has its place. Choose the wrong one and you’ll have sub-optimal results
D. Integrating into existing methods
As with any number of scientific endeavours Deep Learning and Machine Learning requires a combination of Science, Experience based Intuition and Art. Estimating time to develop models will be difficult depending on the type of Question being asked (see above) and the experience of the team. On this basis it is well suited to rapid test and release, as prescribed by Agile methods.
A method for implementation
With these aspects of Deep Learning or Machine Learning adoption in mind, applying them in an agile method will require four (4) key steps (Figure 1.a)
The method is triggered by an area of enquiry (our “why”), based on the a particular business problem and available data.
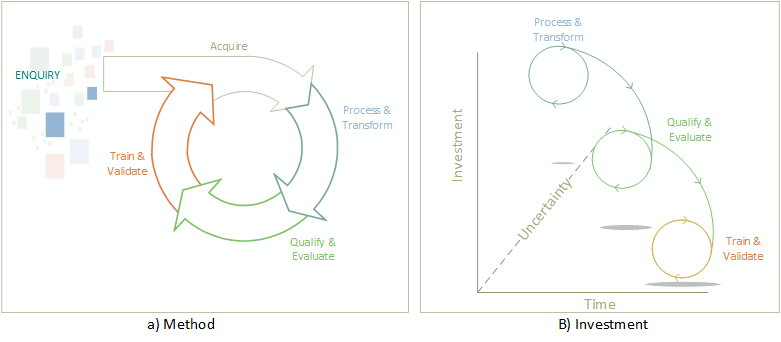
Acquire Stage: The formal identification of data sources, both public and private that can be used in the implementation. With most implementations, you need a significant amount of data to Train, Test and Validate our model. Defining the sourcing strategy, for the initial development and incremental training once complete will be necessary.
Process & Transform Stage: Entails data pre-processing of data sources and shaping data. This will result in identifying the required features necessary to train our model and normalising our values. The output of this stage is essential for evaluating our approach.
Qualify & Evaluate: This stage requires that we evaluate our input data, remove outliers that will impact our accuracy, and determine which algorithms and algorithm/s is best to answer our question. Visualising our data is essential. Note there is often multiple algorithms used depending on your solutions. For example, Deep learning will use different algorithms in layers of our model. A team may spend a large amount of time to evaluate different algorithms, so patience is required.
Train & Validate: The development of the model with the approach decided is undertaken in this stage, using our separated datasets and we evaluate the predictions accuracy. We choose our hyper-parameters, and adjust based on training results. Training a model can take time, and often requires significant intuition as currently its largely a manual undertaking, though the actual coding effort is generally not large when you have an experienced practitioner.
The investment required in execution leans heavily towards the design stage (Figure 1.b above). As we iterate through the phases we reduce our uncertainty and our pace of execution will increase. Once we have a production solution, the pipeline to retrain the model is already build and therefore should be largely automated. Yes, I did say retrain the model – as you gather more data your need to retrain to improve prediction accuracy depending on the type of algorithms used.
It’s an exciting endeavour, and one that can drive enormous benefits if you appreciate the steps to get there. It is still an emerging field, and there are limited toolsets that make development simple, but with the right team you can get the results.